Large language models have revolutionized Artificial Intelligence with their ability to create intelligent responses to inquiries given a prompt and a set of data to pull from.
While there are many ways to make your data available to an AI – some, such as fine tuning, are time consuming, expensive, and inflexible. Other methods such as simply clever prompt creation are inaccurate and often incomplete.
When working with real customers, you often find that to provide a user answer, you must reach across multiple documents.
Lets look at some potential customer inquiries and the sources of those responses:
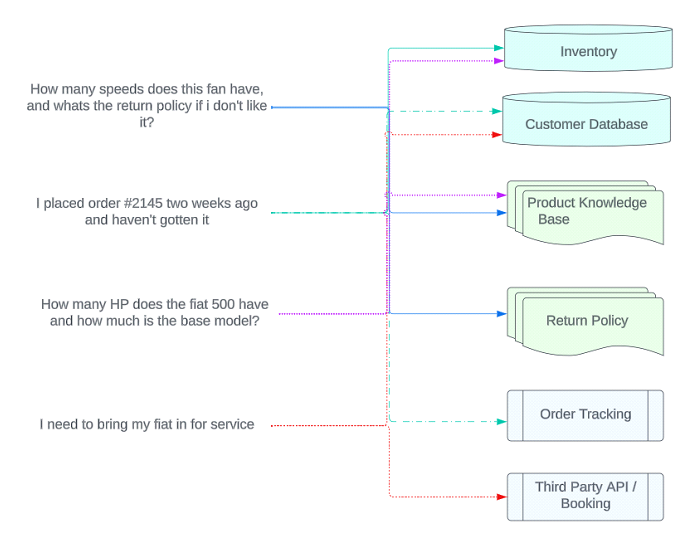
In this example – we see that there are multiple document contexts that need to be available to the AI at any given time in order to be able to give accurate, real time answers. This may be further compounded if your inventory, pricing, order tracking, etc lives behind an API and requires custom integration to work.
Additionally, many are aware of the “token limits” imposed by certain models. Effectively there are only so many words you can send to the AI at one time which limits the amount of data you can throw at an LLM without it breaking. To make matters worse – even if you keep the payload below the data limit, the AI can get confused when there is too much extraneous information and the ability to accurately sift the information becomes increasingly impaired.
AGIS Solves this by utilizing our proprietary AI platform to algorithmically sift through the data to find appropriate information to provide to the LLM before it ever gets to there. This allows us to index thousands of documents across a variety of locations as well as a real time interface to APIs.
By utilizing our algorithmic pre-processing, we create a singular one shot for the LLM with all the context it needs to be able to answer questions accurately, reliably (Less hallucinations, additional unwanted generative contents in the response) and quickly.
The approach of creating a subjective experience for the AI is so powerful it has allowed us to expand quickly across multiple industries. From Government, to University, Medical, Retail to non-chat related Intelligent Automation functions like hands off data transformation (ETL) we’ve proven that LLMs can become exponentially more powerful when given properly contextualized payloads.
Many people understand the generative power of large language models but ignore the fact that LLMs excel at multiple choice questions, or providing answers to simple questions. This means that one of the true superpowers of an LLM is applying logic. Using micropayloads – we can use our algorithmic system to provide a list of options for a given task, and allow the LLM to make the decision. Combining this functionality of the LLM with its generative capabilities enables one to quickly determine possible contexts that the LLM might need – then let the LLM choose the contexts that might be most useful before using the LLM Generative capabilities to create an intelligent response.
In our testing, we have learned that the most efficient way to leverage AI is not to use one AI but combine multiple mechanisms, LLM Logic, Algorithmic and LLM Generative.
Every project we do utilizes our modular technology to build a customized experience for the user in which a combination of multiple AI technologies are leveraged to usher a user’s request through the pipeline and determine how best to answer it.
Here’s a sample of a virtual salesperson architecture we’ve recently implemented:
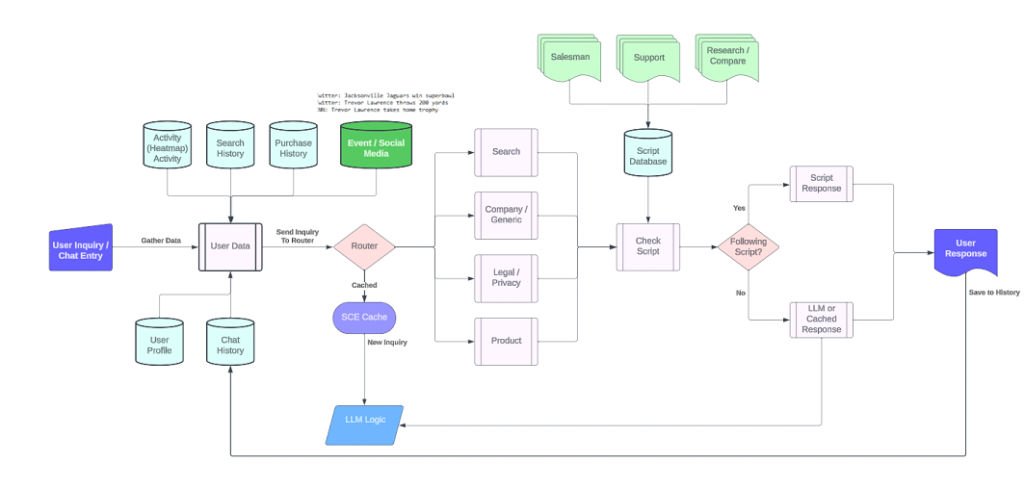
With an AGIS AI – multiple functional and static sources are modularly plugged into a comprehensive solution for your business that can perform anything from static document lookup and search to historical data about your customers and live API integrations for order tracking, knowledge base questions and can even follow a pre-defined script appropriate for the personality. (Customer service, sales, research)
In summary: Leveraging multiple upstream technologies to intelligently sort and prune the inbound information to a large language model can dramatically improve accuracy and the LLM’s ability to gather enough information from multiple sources to respond accordingly.