AGIS Retrieval Augmented Generation
What is Rag?
RAG for LLMs combines real-time information retrieval with text generation, enhancing responses with up-to-date, specific data. The orchestration layer is crucial as it efficiently manages the interaction between retrieval and generation processes, ensuring relevant information is seamlessly integrated into the generated output, thus improving accuracy and relevancy.
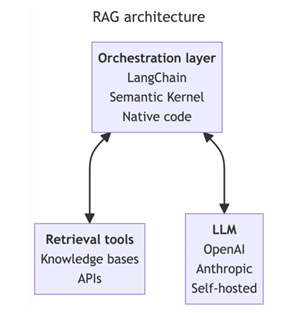
Why Rag?
RAG is used to make AI smarter by letting it look up fresh information from the internet or databases whenever it needs to answer questions. This means it can give more accurate and current answers, solving the problem of AI giving outdated or too general responses based on what it was originally taught.
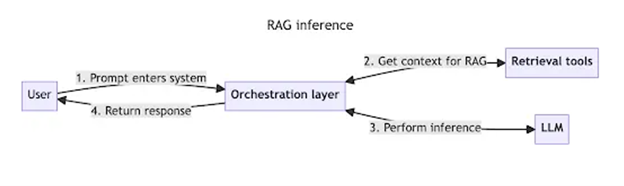
Can an LLM access real time data without RAG?
Without a RAG architecture, a Language Model (LLM) would not inherently know about or utilize real-time data through mechanisms like API calls, live data feeds, web scraping, database integration, event-driven updates, or streaming analytics on its own. These capabilities must be explicitly designed and integrated into the application layer that interacts with the LLM.
What about “training” the models?
Not using a Retrieval-Augmented Generation (RAG) architecture presents several challenges, particularly when it comes to keeping a Language Model (LLM) up-to-date and relevant. Here are the key issues with relying solely on fine-tuning or retraining:
- Costly: Retraining large language models requires significant computational resources. The cost can be prohibitively high, especially for state-of-the-art models, due to the need for powerful hardware and potentially expensive cloud computing services.
- Time-Consuming: The process of retraining or fine-tuning involves not just computational time but also data preparation, model evaluation, and deployment phases. For large models, this process can take weeks or even months, making it impractical for frequent updates.
- Difficulty in Keeping Up-to-Date: The pace at which information changes and new data becomes available can make it nearly impossible for a statically trained model to remain current. Continuous retraining to incorporate the latest information is not feasible for most organizations due to the time and cost involved.
- Data Availability and Quality Issues: Obtaining high-quality, up-to-date training data can be a challenge. Additionally, for many domains, the data may not be available in the required volume or may not reflect the latest trends and information.
- Scalability Concerns: As the amount of information grows, so does the complexity and size of the model needed to capture this knowledge. This escalates the already high costs and time requirements for retraining.
- Inflexibility to New Domains or Rapid Changes: In situations where new topics, terminologies, or significant world events emerge, a model that cannot be quickly updated will lag in accuracy and relevancy, diminishing its effectiveness and user trust.
RAG architectures help mitigate these problems by dynamically incorporating current information at runtime, enabling models to provide responses that reflect the most recent data without the need for continuous retraining. This approach significantly enhances the model’s utility and applicability across various domains and rapidly changing information landscapes.
Does it work with full documents?
Generally speaking, Vector databases, semantic search and other common off the shelf tools are amazing at sentence or paragraph level deduction but the process begins to fail as the documents get longer or the corpus grows. *See alternative processing methods below
AGIS RAG
AGIS uses a traditional RAG architecture but has constructed its own Orchestration layer on top of our AI Platform which has been in development since 2019 – giving us tremendous flexibility, scalability and reliability.
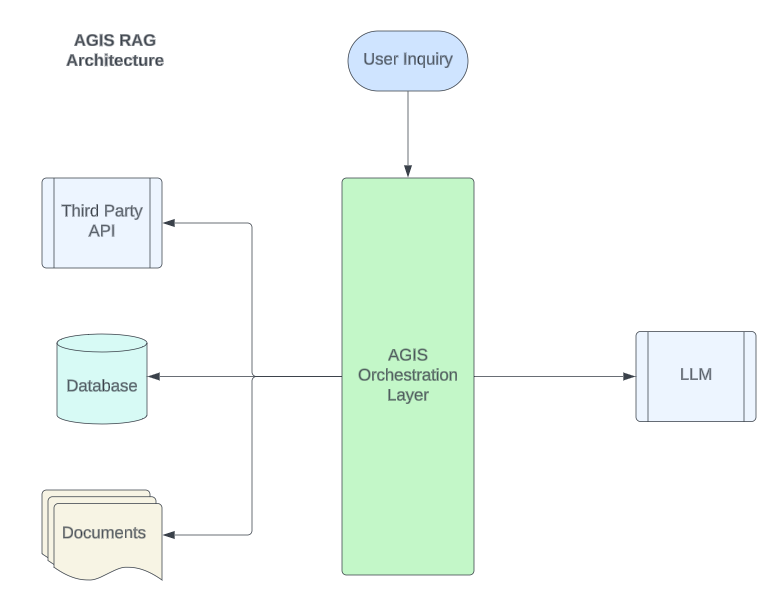
AGIS Large Corpus Handling
AGIS Leverages a proprietary process for executing search results against large corpuses of long documents. Our platform can take a custom approach to the right way of solving a customer’s unique problem. By doing multiple nested summaries, algorithmically excerpting relevant chunks of documents, and using the LLM to make the judgement call, we’ve seen great results at understanding the nuances of complex questions across full documents in huge document stores.
Alternative Processing Methods for Retrieval: Vector Databases, Semantic (Elastic) Search, etc.
When comparing the capabilities of vector databases or semantic search engines to understand the nuance of entire documents versus just sentences or chunks, several specific differences and challenges emerge. These issues primarily stem from the inherent limitations in processing and representing complex, lengthy documents:
- Contextual Limitations:
- Sentence/Chunk Level: When processing on a sentence or chunk level, vector representations can effectively capture the semantic meaning of that specific segment. However, this localized focus may miss broader themes, narratives, or contextual cues that span the entire document.
- Entire Document: Vector representations of entire documents aim to encapsulate the overall theme or subject matter. However, the nuance and specificity present in individual sentences or paragraphs might be diluted or lost. This broad-stroke approach can struggle with capturing detailed nuances, subtle arguments, or specific instances that might be critical for certain search queries.
- Dimensionality and Detail Loss:
- Vectors derived from whole documents have to balance between generalization and specificity. This often leads to a loss of detail where nuanced differences between topics or arguments within the document might not be distinctly represented. For sentences or chunks, while the detail is preserved, the lack of broader context can make it difficult to understand the document’s overall stance or theme.
- Query Matching Complexity:
- Sentence/Chunk Level: Queries matched against sentence-level vectors can yield highly relevant snippets but may fail to capture the document’s overall relevance to the query, especially if the query requires understanding the document’s comprehensive argument or narrative.
- Entire Document: Matching queries against vectors representing entire documents can surface documents that are generally relevant but may overlook specific passages that are critically relevant to the query. This can be particularly problematic for complex queries that depend on understanding the full scope of the document.
- Computational Challenges:
- Generating and processing vectors for entire documents requires significantly more computational resources than for shorter chunks. This can impact search speed and scalability, especially for large document corpora.
- Information Overload and Precision:
- Searches based on entire documents can lead to information overload, where the results are broadly relevant but not precisely what the user is looking for. Conversely, searches based on sentences or chunks might miss the forest for the trees, providing precise but contextually incomplete results.
- Dynamic Content and Structure:
- Documents with dynamic structures (e.g., documents that mix narrative, data, arguments, etc.) pose a challenge for both sentence/chunk-level and entire-document approaches. The former may miss the interplay between different parts of the document, while the latter may not adequately capture the significance of specific sections.
To address these challenges, hybrid approaches are often employed, combining the strengths of sentence/chunk-level processing with whole-document analysis. Techniques such as hierarchical vector representations, context-aware embeddings, and multi-level indexing strategies aim to improve the ability of vector databases and semantic search engines to understand and retrieve documents based on both detailed nuances and overall context.
In Summary:
RAG provides the most cutting edge way currently of accessing data across multiple sources. AGIS’ proprietary full document search orchestration layer provides unparalleled access to information with precise accuracy as it relates to the user’s inquiry. Additionally – our conversational interface turns every into conversation the data.